Как знают многие пользователи, среди новых возможностей VMware vSphere 5.1 есть так называемая Enhanced vMotion или "Shared-Nothing" vMotion - функция, позволяющая переместить работающую виртуальную машину на локальном хранилище ESXi на другой хост и хранилище с помощью комбинации техник vMoton и Storage vMotion в одной операции. Это означает, что для такого типа горячей миграции не требуется общее хранилище (Shared Storage), а значит и затрат на его приобретение. Напомним также, что функция Enhanced vMotion включена во все коммерческие издания VMware vSphere, кроме vSphere Essentials.
Давайте посмотрим поближе, как это все работет:
Сначала приведем требования и особенности работы vMotion при отсутствии общего хранилища:
Хосты ESXi должны находиться под управлением одного сервера vCenter.
Хосты должны находиться в одном контейнере Datacenter.
Хосты должны быть в одной Layer 2 подсети (и, если используется распределенный коммутатор, на одном VDS).
Enhanced vMotion - это исключительно ручной процесс, то есть функции DRS и Storage DRS не будут использовать миграцию машин без общего хранилища. Это же касается и режима обслуживания хоста (Maintenance Mode).
Для одного хоста ESXi может быть проведено не более 2-х Enhanced vMotion единовременно. Таким образом, на хост ESXi может одновременно приходиться максимум 2 штуки Enhanced vMotion и 6 обычных vMotion (всего 8 миграций на хост) + 2 операции Storage vMotion, либо 2 Enhanced vMotion (так как это также задействует Storage vMotion). Подробнее об этом тут.
Enhanced vMotion может проводить горячую миграцию одновременно по нескольким сетевым адаптерам хоста ESXi, если они имеются и настроены корректно.
Миграция Enhanced vMotion может быть проведена только через тонкий клиент vSphere Web Client (в обычном клиенте эта функция недоступна - см. комментарии):
Миграция Enhanced vMotion идет по обычной сети vMotion (а не по Storage Network), по ней передаются и диск ВМ, и ее память с регистрами процессора для обеспечения непрерывной работоспособности виртуальной машины во время миграции:
Теперь как это все работает последовательно. Сначала механизм Enhanced vMotion вызывает подсистему Storage vMotion, которая производит копирование данных по сети vMotion. Здесь важны 2 ключевых компонента - bulk copy и mirror mode driver.
Сначала механизм bulk copy начинает копирование блоков данных с максимально возможной скоростью. Во время этого часть блоков на исходном хранилище хоста может измениться - тут и вступает в дело mirror mode driver, который начинает поддерживать данные блоки на исходном и целевом хранилище в синхронном состоянии.
Mirror mode driver во время своей работы игнорирует те блоки исходного хранилища, которые меняются, но еще не были скопированы на целевое хранилище. Чтобы поддерживать максимальную скорость копирования, Mirror mode driver использует специальный буфер, чтобы не использовать отложенную запись блоков.
Когда диски на исходном и целевом хранилище и их изменяющиеся блоки приходят в синхронное состояние, начинается передача данных оперативной памяти и регистров процессора (операция vMotion). Это делается после Storage vMotion, так как страницы памяти меняются с более высокой интенсивностью. После проведения vMotion идет операция мгновенного переключения на целевой хост и хранилище (Switch over). Это делается традиционным способом - когда различия в памяти и регистрах процессора весьма малы, виртуальная машина на мгновение подмораживается, различия допередаются на целевой хост (плюс переброс сетевых соединений), машина размораживается на целевом хосте и продолжает исполнять операции и использовать хранилище с виртуальным диском уже целевого хоста.
Ну а если вы перемещаете виртуальную машину не между локальными дисками хост-серверов, а между общими хранилищами, к которым имеют доступ оба хоста, то миграция дисков ВМ идет уже по Storage Network, как и в случае с обычным Storage vMotion, чтобы ускорить процесс и не создавать нагрузку на процессоры хостов и сеть vMotion. В этом случае (если возможно) будет использоваться и механизм VAAI для передачи нагрузки по копированию блоков на сторону дискового массива.
Мы уже писали о возможностях новой версии платформы виртуализации VMware vSphere 5.1 и принципах ее лицензирования, однако не затрагивали важного для пользователей продукта - бесплатного VMware vSphere 5.1 Hypervisor (также известен как VMware ESXi 5.1 Free). Напомним, что в версии vSphere 5.1 компания VMware убрала ограничения по памяти виртуальных машин (vRAM) для всех коммерческих изданий VMware vSphere.
Однако это, по-сути, не касается бесплатной версии ESXi:
Бесплатный продукт VMware vSphere Hypervisor 5.1 (Free ESXi 5.1) имеет жесткое ограничение на физическую память хост-сервера ESXi в 32 ГБ. Если физическая RAM сервера превышает 32 ГБ, то бесплатный ESXi просто не будет загружаться.
При этом бесплатный сервер VMware ESXi 5.1 не ограничен по числу физических процессоров.
Что касается остальных ограничений бесплатного ESXi 5.1:
Управление только одним хостом одновременно из vSphere Client (как и раньше)
Отсутствие распределенных сервисов виртуализации (vMotion, HA, DRS, Storage DRS, клонирование ВМ и т.д.)
API в режиме "только для чтения" (то есть невозможность сохранения изменений конфигурации через vCLI)
Отстутсвие Alarms и поддержки SNMP v3, что есть в коммерческой версии
В самом же гипервизоре ESXi 5.1 (в том числе бесплатном) появились следующие новые возможности:
Extended Guest OS and CPU Support - полная поддержка операционных систем Windows Server 2012 и Windows 8, а также новейших процессоров AMD серии "Piledriver" и Intel серий "Ivy Bridge" и "Sandy Bridge".
NEW Improved Security - отсутствие необходимости в общем root-аккаунте при работе с ESXi Shell. Подробности приведены в этом документе (и тут).
NEW Improved Logging and Auditing - логирование активности пользователя в DCUI и по SSH ведется под его аккаунтом, что упрощает анализ логов.
Newvirtual hardware - версия виртуального аппаратного обеспечения (Virtual Hardware) - 9. Это дает до 8 vCPU виртуальных машин, а также обновление VMware Tools без перезагрузки виртуальной машины. Кроме этого, доступны фукнции расширенной виртуализации CPU на хосте, что дает возможность запускать вложенные гипервизоры и ВМ.
Поддержка FC-адаптеров 16 Gbps.
Advanced I/O Device Management - новые команды для траблшутинга FC-адаптеров, а также фабрики SAN, что позволит искать проблемы на пути от HBA-адаптера до порта системы хранения.
SSD Monitoring - возможность отслеживания характеристик функционирования SSD-накопителей через специальный SMART-плагин.
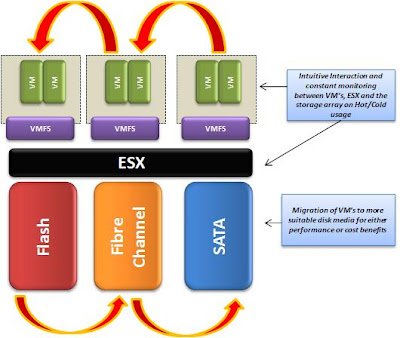
В большой виртуальной инфраструктуре присутствуют сотни хранилищ VMFS, созданных поверх LUN, где лежат виртуальные машины с различным уровнем требуемого сервиса и политик. Проблемы начинаются с того, что система хранения не знает о том, что на ее LUN находятся виртуальные машины. Например, синхронная репликация на уровне массива может делаться только на уровне LUN, хотя с данного тома VMFS требуется реплицировать не все ВМ, которые могут быть с различным уровнем критичности. То же самое касается снапшотов и снапклонов уровня массива...
Мы уже писали о новых возможностях VMware vSphere 5.1 - серверной платформы виртуализации, которая была анонсирована и выпущена на конференции VMowrld 2012. Вместе с выпуском обновленной версии продукта компания VMware внесла достаточно много изменений в издания и политики лицензирования продукта, так как почувствовала сильное давление со стороны основного конкурента - платформы Hyper-V в новой версии ОС Windows Server 2012 со множеством новых возможностей, по совокупности которых инфраструктура Microsoft почти не уступает VMware vSphere.
Итак, основные изменения в изданиях и лицензировании VMware vSphere 5.1:
Полная отмена лимитов по vRAM и числу ядер для лицензии на процессор. Напомним, что ранее (в vSphere 5.0) при превышении суммарного значения сконфигурированной оперативной памяти виртуальных машин (vRAM) для лицензии на процессор определенного издания, пользователи были вынуждены докупать еще лицензий, чтобы соответствовать условиям VMware. Эта политика и раньше вызывала очень много вопросов, так как демотивировала пользователей наращивать коэффициент консолидации виртуальных машин на хостах VMware ESXi (превышаешь порог по памяти для лицензии->платишь больше), что противоречит самой идее виртуализации. Теперь этих ограничений нет, единица лицензирования - физический процессор сервера, при этом не важно сколько в нем ядер и памяти у самого сервера. Мы писали об этом тут.
Во всех изданиях vSphere 5.1, начиная с Essentials Plus, появился виртуальный модуль vSphere Storage Appliance 5.1. Об этом продукте мы уже писали вот тут. Нужен он для создания общего хранилища под виртуальные машины, которое можно создать на базе локальных дисков серверов. Этот продукт обновился и теперь доступен для построения распределенной архитектуры кластеров хранилищ, управляемых через один vCenter.
Издание VMware vSphere 5.1 Standard приобрело множество возможностей. К ним относятся: механизм резервного копирования vSphere Data Protection (подробнее здесь), "горячее" добавление устройств виртуальной машины Hot Add, фреймворк антивирусной защиты vShield Endpoint, возможность репликации виртуальных машин vSphere Replication, кластеры непрерывной доступности vSphere Fault Tolerance и, главное, механизм "горячей" миграции хранилищ виртуальных машин vSphere Storage vMotion.
Издание VMware vSphere 5.1 Essentials Plus приобрело множество возможностей. К ним относятся: механизм резервного копирования vSphere Data Protection (подробнее здесь), фреймворк антивирусной защиты vShield Endpoint и возможность репликации виртуальных машин vSphere Replication.
Важный момент: пользователи vSphere 5.0 теперь не имеют ограничений по vRAM. То есть, изменения в лицензированию имеют обратную силу.
Издание VMware vSphere 5.1 Enterpise Plus позволяет иметь до 64 vCPU виртуальных машин.
Как и всегда, пользователи VMware vSphere 5.0 с действующей подпиской и поддержкой (SnS) обновляются на VMware vSphere 5.1 бесплатно.
Все издания продукта VMware vCenter (Essentials, Foudation и Standard) включают в себя следующие возможности:
Management service – централизованная консоль управления.
Database server – сервер БД.
Inventory service – сервис поиска по виртуальной инфраструктуре, в том числе с несколькими vCenter, а также средства кэширования запросов клиентов, что повышает производительность.
VMware vSphere Clients - "толстая" и "тонкая" консоли администрирования (Web Client теперь основной), позволяющие управлять несколькими vCenter одновременно.
VMware vCenter APIs and .NET Extension – интеграция vCenter со сторонними плагинами.
vCenter Single Sign-On – возможность единовременного логина на сервер без необходимости вводить учетные данные в различных сервисах управления виртуальной инфраструктурой.
Издание Standard, помимо возможности управления неограниченным количеством хост-серверов, предоставляет следующие возможности:
vCenter Orchestrator – средство автоматизации рабочих процессов в виртуальной инфраструктуре.
vCenter Server Linked Mode – общее окружение для нескольких серверов vCenter Server.
На конференции VMworld 2012 компания VMware анонсировала выпуск новой версии серверной платформы виртуализации VMware vSphere 5.1. В обновленной версии продукта появилось множество интересных возможностей, отражающих движение компании VMware в направлении развития облачных вычислений. В этой статье мы приведем полный список новой функциональности VMware vSphere 5.1, которая доступна пользователям уже сегодня...
Компания Microsoft, в преддверии выпуска новой версии своего гипервизора Hyper-V 3.0 в составе ОС Windows Server 2012, предпринимает множество шагов по убеждению пользователей в том, что следует переходить на платформу Microsoft с продукта VMware vSphere.
Напомним основные мероприятия Microsoft, проделанные в последнее время:
Новая схема лицензирования Windows Server 2012, где издания Standard и Datacenter равны по функциональности, за исключением различного количества лиценцируемых виртуальных машин на хосте. В данной схеме особенно подчеркивается, что ограничения на память виртуальных машин (в отличие от vSphere) - нет.
Теперь подоспело еще одно средство, подталкивающее пользователей к миграции на платформу Hyper-V - плагин Virtual Machine Converter Plug-in for VMware vSphere Client, находящийся сейчас в бета-версии. Этот плагин позволяет администратору VMware vSphere провести миграцию виртуальной машины на vSphere через пункт контекстного меню ВМ. Поддерживаются клиенты vSphere Client 4.1 и 5.0.
Основные возможности продукта MVMC:
Миграция виртуальных машин с хостов VMware vSphere на платформу Hyper-V в составе:
Windows Server 2012 Release Candidate.
Microsoft Hyper-V Server 2012 Release Candidate
Добавление сетевых адаптеров (NICs) сконвертированным на Hyper-V машинам.
Настройка функций dynamic memory на сконвертированной машине.
Поддержка миграции ВМ, которые находятся в кластере VMware HA/DRS.
Поддержка миграции ВМ в Failover Cluster на Hyper-V.
Скачать Virtual Machine Converter Plug-in for VMware vSphere Client можно по этой ссылке.
Недавно мы уже писали о том, как работает технология балансировки нагрузки на хранилища VMware Storage DRS (там же и про Profile Driven Storage). Сегодня мы посмотрим на то, как эта технология работает совместно с различными фичами дисковых массиов, а также функциями самой VMware vSphere и других продуктов VMware.
Для начала приведем простую таблицу, из которой понятно, что поддерживается, а что нет, совместно с SDRS:
Возможность
Поддерживается или нет
Рекомендации VMware по режиму работы SDRS
Снапшоты на уровне массива (array-based snapshots)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Дедупликация на уровне массива (array-based deduplication)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Использование "тонких" дисков на уровне массива (array-based thin provisioning)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Использование функций автоматического ярусного хранения (array-based auto-tiering)
Поддерживается
Ручное применение рекомендаций (Manual Mode), только для распределения по заполненности хранилищ (auto-tiering по распределению нагрузки сам решит, что делать)
Репликация на уровне массива (array-based replication)
Автоматическое применение рекомендаций (Fully Automated Mode)
Технология репликации на уровне хоста (VMware vSphere Replication)
Не поддерживается
-----
Снапшоты виртуальных машин (VMware vSphere Snapshots)
Поддерживается
Автоматическое применение рекомендаций (Fully Automated Mode)
Использование "тонких" дисков на уровне виртуальных хранилищ (VMware vSphere Thin Provisioning)
Поддерживается
Автоматическое применение рекомендаций (Fully Automated Mode)
Технология связанных клонов (VMware vSphere Linked Clones)
Не поддерживается
-----
"Растянутый" кластер (VMware vSphere Storage Metro Cluster)
Поддерживается
Ручное применение рекомендаций (Manual Mode)
Хосты с версией ПО, младше чем vSphere 5.0
Не поддерживается
-----
Использование совместно с продуктом VMware vSphere Site Recovery Manager
Не поддерживается
-----
Использование совместно с продуктом VMware vCloud Director
Не поддерживается
-----
Комментарии к таблице:
Снапшоты на уровне массива - они никак не влияют на работу механизма SDRS, однако рекомендуется оставить его в ручном режиме, чтобы избежать возможных проблем при одновременном создании снапшота и перемещении виртуальных дисков.
Дедупликация на уровне массива - полностью совместима со механизмом SDRS, однако рекомендуется ручной режим, так как, с точки зрения дедупликации, наиболее эффективно сначала применить рекомендации по миграции виртуальных дисков, а потом уже использовать дедупликацию (для большинства сценариев).
Использование array-based auto-tiering - очевидно, что функции анализа производительности в дисковом массиве и перемещения данных по ярусам с различными характеристиками могут вступить вступить в конфликт с алгоритмами определения нагрузки в SDRS и перемещения vmdk-дисков по хранилищам на логическом уровне. Сам Storage DRS вступает в действие после 16 часов анализа нагрузки и генерирует рекомендации каждые 8 часов, в дисковом же массиве механизм перераспределения блоков по ярусам может работать по-разному: от real-time процесса в High-end массивах, до распределения каждые 24 часа в недорогих массивах. Понятно, что массиву лучше знать, какие блоки куда перемещать с точки зрения производительности физических устройств, поэтому для SDRS рекомендуется оставить выравнивание хранилищ только по заполненности томов VMFS, с отключенной I/O Metric.
Репликация на уровне массива - полностью поддерживается со стороны SDRS, однако, в зависимости от использования метода репликации, во время применения рекомендаций SDRS виртуальные машины могут остаться в незащищенном состоянии. Поэтому рекомендуется применять эти рекомендации SDRS во время запланированного окна обслуживания хранилищ.
VMware vSphere Storage Metro Cluster - здесь нужно избегать ситуации, когда виртуальный диск vmdk машины может уехать на другой сайт по отношению к хосту ESXi, который ее исполняет (когда используется общий Datastore Cluster хранилищ). Поэтому, а еще и потому, что распределенные кластеры могут строиться на базе технологий синхронной репликации хранилищ (см. предыдущий пункт), нужно использовать ручное применение рекомендаций SDRS.
Поддержка VMware vSphere Site Recovery Manager - на данный момент SDRS не обнаруживает Datastore Groups в SRM, а SRM не отслеживает миграции SDRS по хранилищам. Соответственно, при миграции ВМ на другое хранилище не обновляются protection groups в SRM, как следствие - виртуальные машины оказываются незащищенными. Поэтому совместное использование этих продуктов не поддерживается со стороны VMware.
Поддержка томов RDM - SDRS полностью поддерживает тома RDM, однако эта поддержка совершенно ничего не дает, так как в миграциях может участвовать только vmdk pointer, то есть прокси-файл виртуального диска, который занимает мало места (нет смысла балансировать по заполненности) и не генерирует никаких I/O на хранилище, где он лежит (нет смысла балансировать по I/O). Соответственно понадобиться эта поддержка может лишь на время перевода Datastore, где лежит этот файл-указатель, в режим обслуживания.
Поддержка VMware vSphere Replication - SDRS не поддерживается в комбинации с хостовой репликацией vSphere. Это потому, что файлы *.psf, используемые для нужд репликации, не поддерживаются, а даже удаляются при миграции ВМ на другое хранилище. Вследствие этого, механизм репликации для смигрированной машины считает, что она нуждается в полной синхронизации, что вызывает ситуацию, когда репликация будет отложена, а значит существенно ухудшатся показатели RTO/RPO. Поэтому (пока) совместное использование этих функций не поддерживается.
Поддержка VMware vSphere Snapshots - SDRS полностью поддерживает спапшоты виртуальных машин. При этом, по умолчанию, все снапшоты и виртуальные диски машины при применении рекомендаций перемещаются на другое хранилище полностью (см. левую часть картинки). Если же для дисков ВМ настроено anti-affinity rule, то они разъезжаются по разным хранилищам, однако снапшоты едут вместе со своим родительским диском (см. правую часть картинки).
Использование тонких дисков VMware vSphere - полностью поддерживается SDRS, при этом учитывается реально потребляемое дисковое пространство, а не заданный в конфигурации ВМ объем виртуального диска. Также SDRS учитывает и темпы роста тонкого виртуального диска - если он в течение последующих 30 часов может заполнить хранилище до порогового значения, то такая рекомендация показана и применена не будет.
Технология Linked Clones - не поддерживается со стороны SDRS, так как этот механизм не отслеживает взаимосвязи между дисками родительской и дочерних машин, а при их перемещении между хранилищами - они будут разорваны. Это же значит, что SDRS не поддерживается совместно с продуктом VMware View.
Использование с VMware vCloud Director - пока не поддерживается из-за проблем с размещением объектов vApp в кластере хранилищ.
Хосты с версией ПО, младше чем vSphere 5.0 - если один из таких хостов поключен к тому VMFS, то для него SDRS работать не будет. Причина очевидна - хосты до ESXi 5.0 не знали о том, что будет такая функция как SDRS.
Мы уже много писали о продукте vGate R2 - средстве номер 1 для защиты виртуальной инфраструктуры VMware vSphere, которое полностью поддерживает пятую версию этой платформы, имеет сертификаты ФСТЭК и предназначено для безопасной настройки хост-серверов и ВМ средствами политик, а также защиты от НСД. В прошлых статьях мы рассказывали о защите облачных инфраструктур сервис-провайдеров от внутренних и внешних угроз. Сегодня мы постараемся обобщить угрозы, существующие в виртуальной среде, и предложить средства защиты на базе продукта vGate R2 и других решений от компании Код Безопасности.
Многие интересующиеся значимыми событиями, происходящими на рынке виртуализации, уже, наверное, читали о том, что VMware приобрела компанию Nicira за 1,26 миллиарда долларов (из них $1,05 млрд. - кэшем, что весьма много). Сумма этой сделки заставляет обратить на нее внимание и задуматься над тем, как ведущие компании в сфере облачных вычислений видят себе будущее частных облаков.
Для начала небольшой видео-обзор решения Nicira (основной продукт компании - Nicira Network Virtualization Platform ):
Из ролика ничего не понятно - это неудивительно, поскольку технология эта фундаментальная и весьма непростая. Начнем с проблемы, которая существует в крупных компаниях по всему миру, использующих технологии виртуализации на платформе VMware vSphere. Крутые и большие организации уже давно видят виртуализацию не только как платформу, но и как основу существования облаков в контексте абстракции вычислительных ресурсов:
Основа данной концепции такова: мы берем различное железо и хранилища, которые есть в нашем датацентре, объединяем их в общий пул с помощью платформы виртуализации серверов. Далее эти вычислительные мощности и стораджи мы отделяем от логической ценностной единицы ИТ - приложений - с помощью абстракций - виртуальных машин и виртуальных хранилищ. Общий вычислительный пул датацентра мы разрезаем на логически удобные нам единицы (пулы ресурсов) и дальше предоставляем пользователям виртуальные машины с соответствующим уровнем SLA из абстрактных сущностей, которые построены поверх оборудования и вычислительной архитектуры с определенными характеристиками. Делается это с помощью VMware vCloud Director с его концепцией виртуальных датацентров:
Следующий аспект: виртуальные машины существуют на серверах и хранилищах уже на логическом, а не на физическом уровне (независимо от вендоров железа), как сделать так, чтобы в датацентре они были защищены политиками, да и сам периметр датацентра тоже был защищен? Ответ прост - есть семейство продуктов VMware vShield:
Прекрасно. Вроде все? Нет, не все. Невиртуализованной у нас осталась еще одна часть, а именно - сети. VMware предоставляет нам распределенный виртуальный коммутатор (Distributed vSwitch) с базовыми технологиями изоляции и контроля (Private VLAN), есть также продукт от Cisco - Nexus 1000V, который выполняет схожие функции, но обладает более широкими возможностями. Все это делается на уровне абстракции сетевых интерфейсов хост-серверов.
Однако в данном подходе нет самого главного - средств абстракции и виртуализации физического сетевого оборудования (коммутаторов, маршрутизаторов), большим парком которых применительно к виртуальным машинам нужно централизованно управлять в датацентре компании, где есть сотни виртуальных сетей, политик и конфигураций. Все это приводит к тому, что на развертывание новой виртуальной машины уходит 2-3 минуты (на сервере+хранилище), а вот на настройку сетевого взаимодействия, VLAN, безопасности, политик и прочего в забюрократизированных организациях уходит несколько дней.
Вот эту фундаментальную проблему и решает компания Nicira, так недешево доставшаяся VMware:
Суть концепции Nicira применительно к сетевому взаимодействию та же самая, что и в серверной виртуализации: собираем весь набор сетевого оборудования разных вендоров в единый пул, где уже на логическом уровне определяем виртуальные сети и политики, после чего можем цеплять их к виртуальным машинам централизованно:
Все это называется программно-определяемые сети (Software-defined networking, SDN) и работает на базе программных решений, разрабатываемых Nicira с далекого 2007 года. Интересно, что основательница VMware, Диана Грин, которую двинули с поста CEO компании, была одним из инвесторов Nicira, о чем мы писали 2 года назад. Диана вышла с неплохим профитом, а Nicira теперь позволит VMware получить законченную концепцию полной виртуализации облачного датацентра. Как нам и обещали, VMware вполне может стать "VMware of Networking". Кстати, теперь при покупке Nicira компания VMware снова двигает своего CEO.
Если тема вам интересна, можно почитать следующие материалы:
Ну и следующая новость - покупка компанией VMware конторы DynamicOps (продукт Virtual Resource Manager, VRM). Эта контора была выделена из небезызвестного банка Credit Suisse и разрабатывает средства для автоматизации гибридных облаков на базе нескольких гипервизоров (что неизбежно будет в крупных организациях с приходом Hyper-V 3.0), а также средства управления сервисными архитектурами вроде Platform-as-a-Service, Database-as-a-Service и Storage-as-a-Service.
Виктор прислал мне презентацию от того самого Ивана, который на одной из юзер-групп VMware рассматривал особенности дизайна и проектирования виртуальной инфраструктуры VMware vSphere. Часть, касающаяся виртуализации различных типов нагрузок в гостевых ОС виртуальных машин показалась мне очень интересной, поэтому я решил перевести ее и дополнить своими комментариями и ссылками. Итак, что следует учитывать при переносе и развертывании различных приложений в виртуальных машинах на платформе vSphere.
Таги: VMware, vSphere, ESXi, HA, Enterprise, VMachines
В первой части статьи о продукте vGate R2, предназначенном для защиты виртуальной инфраструктуры VMware vSphere, мы рассмотрели механизмы того, как с помощью него можно защитить инфраструктуру сервис-провайдера от внешних уроз в сфере информационной безопасности. В этой части статьи мы рассмотрим не менее важный аспект защиты инфраструктуры виртуализации - защиту от внутренних (инсайдерских) угроз в датацентрах средствами сертифицированного ФСТЭК решения vGate R2.
Одним из ключевых нововведений VMware vSphere 5, безусловно, стала технология выравнивания нагрузки на хранилища VMware vSphere Storage DRS (SDRS), которая позволяет оптимизировать нагрузку виртуальных машин на дисковые устройства без прерывания работы ВМ средствами технологии Storage vMotion, а также учитывать характеристики хранилищ при их первоначальном размещении.
Основными функциями Storage DRS являются:
Балансировка виртуальных машин между хранилищами по вводу-выводу (I/O)
Балансировка виртуальных машин между хранилищами по их заполненности
Интеллектуальное первичное размещение виртуальных машин на Datastore в целях равномерного распределения пространства
Учет правил существования виртуальных дисков и виртуальных машин на хранилищах (affinity и anti-affinity rules)
Ключевыми понятими Storage DRS и функции Profile Driven Storage являются:
Datastore Cluster - кластер виртуальных хранилищ (томов VMFS или NFS-хранилищ), являющийся логической сущностью в пределах которой происходит балансировка. Эта сущность в чем-то похожа на обычный DRS-кластер, который составляется из хост-серверов ESXi.
Storage Profile - профиль хранилища, используемый механизмом Profile Driven Storage, который создается, как правило, для различных групп хранилищ (Tier), где эти группы содержат устройства с похожими характеристиками производительности. Необходимы эти профили для того, чтобы виртуальные машины с различным уровнем обслуживания по вводу-выводу (или их отдельные диски) всегда оказывались на хранилищах с требуемыми характеристиками производительности.
При создании Datastore Cluster администратор указывает, какие хранилища будут в него входить (максимально - 32 штуки в одном кластере):
Как и VMware DRS, Storage DRS может работать как в ручном, так и в автоматическом режиме. То есть Storage DRS может генерировать рекомендации и автоматически применять их, а может оставить их применение на усмотрение пользователя, что зависит от настройки Automation Level.
С точки зрения балансировки по вводу-выводу Storage DRS учитывает параметр I/O Latency, то есть round trip-время прохождения SCSI-команд от виртуальных машин к хранилищу. Вторым значимым параметром является заполненность Datastore (Utilized Space):
Параметр I/O Latency, который вы планируете задавать, зависит от типа дисков, которые вы используете в кластере хранилищ, и инфраструктуры хранения в целом. Однако есть некоторые пороговые значения по Latency, на которые можно ориентироваться:
SSD-диски: 10-15 миллисекунд
Диски Fibre Channel и SAS: 20-40 миллисекунд
SATA-диски: 30-50 миллисекунд
По умолчанию рекомендации по I/O Latency для виртуальных машин обновляются каждые 8 часов с учетом истории нагрузки на хранилища. Также как и DRS, Storage DRS имеет степень агрессивности: если ставите агрессивный уровень - миграции будут чаще, консервативный - реже. Первой галкой "Enable I/O metric for SDRS recommendations" можно отключить генерацию и выполнение рекомендаций, которые основаны на I/O Latency, и оставить только балансировку по заполненности хранилищ.
То есть, проще говоря, SDRS может переместить в горячем режиме диск или всю виртуальную машину при наличии большого I/O Latency или высокой степени заполненности хранилища на альтернативный Datastore.
Самый простой способ - это балансировка между хранилищами в кластере на базе их заполненности, чтобы не ломать голову с производительностью, когда она находится на приемлемом уровне.
Администратор может просматривать и применять предлагаемые рекомендации Storage DRS из специального окна:
Когда администратор нажмет кнопку "Apply Recommendations" виртуальные машины за счет Storage vMotion поедут на другие хранилища кластера, в соответствии с определенным для нее профилем (об этом ниже).
Аналогичным образом работает и первичное размещение виртуальной машины при ее создании. Администратор определяет Datastore Cluster, в который ее поместить, а Storage DRS сама решает, на какой именно Datastore в кластере ее поместить (основываясь также на их Latency и заполненности).
При этом, при первичном размещении может случиться ситуация, когда машину поместить некуда, но возможно подвигать уже находящиеся на хранилищах машины между ними, что освободит место для новой машины (об этом подробнее тут):
Как видно из картинки с выбором кластера хранилищ для новой ВМ, кроме Datastore Cluster, администратор первоначально выбирает профиль хранилищ (Storage Profile), который определяет, по сути, уровень производительности виртуальной машины. Это условное деление хранилищ, которое администратор задает для хранилищ, обладающих разными характеристиками производительности. Например, хранилища на SSD-дисках можно объединить в профиль "Gold", Fibre Channel диски - в профиль "Silver", а остальные хранилища - в профиль "Bronze". Таким образом вы реализуете концепцию ярусного хранения данных виртуальных машин:
Выбирая Storage Profile, администратор будет всегда уверен, что виртуальная машина попадет на тот Datastore в рамках выбранного кластера хранилищ, который создан поверх дисковых устройств с требуемой производительностью. Профиль хранилищ создается в отельном интерфейсе VM Storage Profiles, где выбираются хранилища, предоставляющие определенный набор характеристик (уровень RAID, тип и т.п.), которые платформа vSphere получает через механизм VASA (VMware vStorage APIs for Storage Awareness):
Ну а дальше при создании ВМ администратор определяет уровень обслуживания и характеристики хранилища (Storage Profile), а также кластер хранилища, датасторы которого удовлетворяют требованиям профиля (они отображаются как Compatible) или не удовлетворяют им (Incompatible). Концепция, я думаю, понятна.
Регулируются профили хранилищ для виртуальной машины в ее настройках, на вкладке "Profiles", где можно их настраивать на уровне отдельных дисков:
На вкладке "Summary" для виртуальной машины вы можете увидеть ее текущий профиль и соответствует ли в данный момент она его требованиям:
Также можно из оснастки управления профилями посмотреть, все ли виртуальные машины находятся на тех хранилищах, профиль которых совпадает с их профилем:
Далее - правила размещения виртуальных машин и их дисков. Определяются они в рамках кластера хранилищ. Есть 3 типа таких правил:
Все виртуальные диски машины держать на одном хранилище (Intra-VM affinity) - установлено по умолчанию.
Держать виртуальные диски обязательно на разных хранилищах (VMDK anti-affinity) - например, чтобы отделить логи БД и диски данных. При этом такие диски можно сопоставить с различными профилями хранилищ (логи - на Bronze, данны - на Gold).
Держать виртуальные машины на разных хранилищах (VM anti-affinity). Подойдет, например, для разнесения основной и резервной системы в целях отказоустойчивости.
Естественно, у Storage DRS есть и свои ограничения. Основные из них приведены на картинке ниже:
Основной важный момент - будьте осторожны со всякими фичами дискового массива, не все из которых могут поддерживаться Storage DRS.
И последнее. Технологии VMware DRS и VMware Storage DRS абсолютно и полностью соместимы, их можно использовать совместно.
Как знают пользователи виртуализации от Microsoft, в средстве управления System Center Virtual Machine Manager 2008 R2 имелась функция Performance and Resource Optimization (PRO), которая позволяла осуществлять балансировку нагрузки на хост-серверы виртуальной инфраструктуры Hyper-V. Происходит это путем горячей миграции виртуальных машин с загруженных на незагруженные хосты, за счет использования пороговых значений на хостах, задаваемых пользователем (т.е. превышение лимитов памяти или утилизации процессора). По-сути, это аналог VMware DRS в VMware vSphere (и даже Storage DRS, поскольку через партнерские решения могут отслеживаться параметры производительности хранилищ). Миграция виртуальных машин в соответствии с рекомендациями PRO может проводиться автоматически или вручную:
Большим недостатком данной технологии было то, что она требовала наличия продукта System Center Operations Manager, который есть далеко не у всех СМБ-пользователей.
В System Center Virtual Machine Manager 2012 технология PRO была заменена на техники Dynamic Optimization и Power Optimization, которые уже, к счастью, не зависят от Operations Manager и не требуют его. Также появились функции Power Optimization, которые позволяют отключать хост-серверы Hyper-V с малой нагрузкой, за счет миграции с них виртуальных машин (также по пороговым значениям, задаваемым пользователем), в целях экономии электроэнергии (аналог VMware Distributed Power Management, который является частью технологии DRS).
Dynamic Optimization и Power Optimization в SC VMM 2012 позволяют нам настроить следующие параметры:
Степерь агрессивности Dynamic Optimization при применении рекомендаций в кластере или группе хостов (Host group)
Автоматический или ручной режим работы
Интервал между генерациями и применением рекомендаций (по умолчанию 10 минут)
Использовать или нет Power Optimization
Окно (промежуток времени в течение суток), в котое Power Optimization будет работать
Так выглядят настройки Dynamic Optimization:
Пользователь определяет минимальные значения доступных ресурсов при размещении виртуальных машин на хостах:
Обратите, внимание, что пороговые значения могут быть заданы и для Disk I/O, т.е. виртуальную машину можно смигрировать не только между хостами, но и хранилищами средствами технологии Storage Live Migration.
Хосты, находящиеся в режиме обслуживания (maintenance mode) исключаются из механизма Dynamic Optimization.
А так настройка окна Power Optimization:
Все очень просто - ночью нагрузка спадает и можно смигрировать виртуальные машины с некоторых хостов, а сами хосты выключить. Потом окно заканчивается (начинается рабочий день) - хосты включаются, виртуальные машины переезжают на них, а Power Optimization не вмешивается.
Таким образом, получается, что Dynamic Optimization и Power Optimization в System Center Virtual Machine Manager 2012 представляют собой аналог VMware DRS и sDRS, что будет очень приятным моментом при использовании SC VMM 2012 с Hyper-V 3.0. И напоследок отметим, что функции Dynamic Optimization и Power Optimization в VMM 2012 работают при управлении не только хостами Hyper-V, но и платформами VMware vSphere и Citrix XenServer.
Но все же отличие Dynamic Optimization от VMware DRS есть - для Dynamic Optimization нельзя задавать Anti-affinity rules, что может оказаться некоторым неудобством для администраторов.
Как многие из вас знают, в среде VMware vSphere есть специализированные виртуальные машины, которую выполняют служебные функции, специфические для виртуальной инфраструктуры. К ним, например, можно отнести, виртуальные агенты (Agent VMs) - машины, предназначенные для того, чтобы присутствовать на хосте всегда (т.е. не участвовать в DRS/DPM) и обслуживать другие ВМ. Хороший пример - это антивирусные виртуальные модули (Virtual Appliance), которые сейчас есть у Trend Micro и Касперского и которые работают через vShield Endpoint и VMsafe API:
Логично предположить, что эти виртуальные машины в среде VMware vSphere надо обрабатывать как-то по-особенному. Это так и происходит. Давайте посмотрим, как это делается:
1. Платформа vSphere помечает внутри себя такие виртуальные машины как виртуальные агенты (Agent VMs).
2. Поскольку виртуальный агент должен предоставлять сервис для других виртуальных машин, агенские ВМ, в случае сбоя, на каждом хосте запускаются в первую очередь, чтобы не оставить никого без этого сервиса.
Таким образом, в случае сбоя порядок загрузки ВМ на хосте ESXi следующий:
стартуют виртуальные агенты
запускаются Secondary виртуальные машины для тех, которые защищены технологией Fault Tolerance
поднимаются виртуальные машины с высоким, средним и низким приоритетом, соответственно
3. Механизм VMware DRS/DPM, осуществляющий балансировку виртуальных машин по хостам средствами vMotion и экономию электропитания серверов средствами их отключения при недогрузке датацентра, также в курсе о виртуальных агентах. Поэтому здесь следующее поведение:
DRS учитывает Reservations, заданные для агентов, даже в том случае, когда они выключены
для режимов обслуживания (maintenance mode) и Standby - виртуальные агенты никуда с хоста автоматически не мигрируют
виртуальные агенты должны быть доступны на хосте перед тем, как там будут включены обычные ВМ или они туда будут смигрированы
На конференции VMware Partner Exchange 2012, прошедшей с 13 по 16 февраля в Лас-Вегасе, произошло интресное событие: небезызвестная компания Евгения Касперского, выпускающая антивирус с одноименным названием, анонсировала решение Kaspersky Security for Virtualization, обеспечивающее защиту виртуальных машин, работающих на VMware View, средствами технологии VMware VMsafe. Ну и заодно защищаются и виртуальные серверы (но для них это не так актуально как для виртуальных ПК).
О VMsafe мы уже не раз писали (тут и тут). Основное преимущество данной технологии - возможность предоставления сторонним вендорам специального API гипервизора (VMsafe и EPSEC), посредством которого специальная виртуальная машина (виртуальный модуль - Virtual Applaince) может сканировать все проходящии через гипервизор инструкции, обнаруживать угрозы и предотвращать воздействие вредоносного ПО. Это позволяет не устанавливать антивирус в каждую виртуальную машину, а использовать по одной служебной ВМ на каждом хосте, о которой знает VMware vSphere (это знание выражается, например, в том, что машина не перемещается между хостами средствами VMware vMotion/DRS).
Преимущества такого подхода очевидны - не требуется устанавливать агентов в гостевые ОС виртуальных машин, не расходуется системных ресурсов хост-сервера на работу пачки агентов (а количество виртуальных ПК на хосте иногда доходит до сотни) и виртуальная машина оказывается защищена сразу после ее запуска. Ну и плюс ко всему, не происходит так называемых "антивирусных штормов", когда сканирование запускается на всех машинах одновременно.
Европейский запуск продукта Kaspersky Security for Virtualization состоится на выставке CeBIT, которая пройдет в Ганновере 6 марта 2012 года.
Решение Kaspersky Security for Virtualization будет интегрировано в консоль Kaspersy Security Center 9.0, что позволит управлять антивирусной защитой виртуальных и физических машин из единой консоли.
Релиз Kaspersky Security for Virtualization должен состояться в середне-конце весны этого года, а пока можно почитать следующие материалы:
Таким образом, число производителей антивирусных решений, поддерживающих VMware VMsafe и vShield Endpoint увеличилось. Напомним, что аналогичные функции защиты виртуальных сред предоставляет компания Trend Micro в решении DeepSecurity:
Alan Renouf, автор множества полезных скриптов PowerCLI для администрирования инфраструктуры VMware vSphere, выпустил очередное обновление своей бесплатной утилиты vCheck 6.
vCheck 6 - это PowerCLI-скрипт, который готовит отчетность по объектам окружения VMware vSphere и отсылает результат на почту администратора, из которого можно узнать о текущем состоянии виртуальной инфраструктуры и определить потенциальные проблемы.
Пример получаемого отчета можно посмотреть тут (кликабельно):
Вот полный список того, что может выдавать скрипт vCheck 6:
General Details
Number of Hosts
Number of VMs
Number of Templates
Number of Clusters
Number of Datastores
Number of Active VMs
Number of Inactive VMs
Number of DRS Migrations for the last days
Snapshots over x Days old
Datastores with less than x% free space
VMs created over the last x days
VMs removed over the last x days
VMs with No Tools
VMs with CD-Roms connected
VMs with Floppy Drives Connected
VMs with CPU ready over x%
VMs with over x amount of vCPUs
List of DRS Migrations
Hosts in Maintenance Mode
Hosts in disconnected state
NTP Server check for a given NTP Name
NTP Service check
vmkernel warning messages ov the last x days
VC Error Events over the last x days
VC Windows Event Log Errors for the last x days with VMware in the details
VC VMware Service details
VMs stored on datastores attached to only one host
VM active alerts
Cluster Active Alerts
If HA Cluster is set to use host datastore for swapfile, check the host has a swapfile location set
Host active Alerts
Dead SCSI Luns
VMs with over x amount of vCPUs
vSphere check: Slot Sizes
vSphere check: Outdated VM Hardware (Less than V7)
VMs in Inconsistent folders (the name of the folder is not the same as the name)
VMs with high CPU usage
Guest disk size check
Host over committing memory check
VM Swap and Ballooning
ESXi hosts without Lockdown enabled
ESXi hosts with unsupported mode enabled
General Capacity information based on CPU/MEM usage of the VMs
vSwitch free ports
Disk over commit check
Host configuration issues
VCB Garbage (left snapshots)
HA VM restarts and resets
Inaccessible VMs
Плюс ко всему, скрипт имеет расширяемую структуру, то есть к нему можно добавлять свои модули для различных аспектов отчетности по конкретным приложениям. Список уже написанных Аланом плагинов можно найти на этой странице.
Вот эта заметка на блоге VMware напомнила об одной интересной особенности поведения правил совместного и несовместного размещения виртуальных машин на хосте ESX/ESXi (DRS Host Affinity Rules).
Напомним, что для виртуальных машин в класетере DRS можно задавать данные правила для ситуаций, когда требуется определенным образом распределять группы виртуальных машин по хостам или их группам. Требуется это обычно для соблюдения правил лицензирования (см., например, правила лицензирования для ВМ Oracle), когда виртуальные машины могут исполняться только на определенных физических серверах, либо для всяких экзотических ситуаций, когда, к примеру, основную и резервную системут нужно держать на разных хостах.
То есть, мы задаем группы виртуальных машин и хостов:
И указываем, что виртуальные машины DRS-группы могут работать только на данной DRS-группе хостов:
Правила эти бывают мягкими (preferential), когда DRS+HA будут стараться следовать им при штатном функционировании кластера, и жесткими (mandatory, "Must run") - в этом случае ни при каких условиях виртуальные машины не переедут на хосты не из группы. Этого не произойдет ни средствами vMotion/DRS/Maintenance Mode, ни средствами перезапуска HA в аварийных ситуациях.
Для жестких правил есть один интересный аспект: они сохраняются и продолжают действовать даже тогда, когда вы отключили кластер VMware DRS. То есть вы не сможете сделать ручной vMotion или Power On машин на хостах не из группы, а HA не будет их там перезапускать. При этом в настройках кластера с отключенным DRS уже не будет возможности редактирования этих правил (категория VMware DRS пропадет). Это сделано для того, чтобы во время временных сбоев (например, vCenter) лицензионные правила существования ВМ для приложений на хостах не нарушались в любом случае.
Поэтому, если нужно удалить правила, нужно снова включить DRS, удалить их и снова отключить DRS.
Таги: VMware, DRS, Обучение, vSphere, ESX, ESXi, vMotion, HA
В последнее время все больше пользователей виртуализуют критичные базы данных под управлением СУБД Oracle в виртуальных машинах VMware vSphere. При этом есть миф о том, что Oracle не поддерживает свои СУБД в виртуальных машинах, и, если что-то случится, то получить техническую поддержку будет невозможно. Это не так.
Техническая поддержка Oracle для ВМ на VMware vSphere
На самом деле у Oracle есть документ "MyOracleSupport Document ID #249212" в котором прописаны принципы работы с техподдержкой при работе СУБД в ВМ VMware vSphere:
Вкратце их можно изложить так:
1. Действительно, Oracle не сертифицирует работу своих СУБД в виртуальных машинах VMware.
2. Если у вас возникает проблема с БД Oracle в виртуальной машине VMware, то Oracle смотрит, есть ли подобная проблема для физической системы, либо вы можете продемонстрировать, что проблема повторяется на физической машине, а не только в ВМ. Если проблема относится именно к виртуальной машине и не проявляется на физической системе, либо решение от техподдержки Oracle работает только для физического сервера - вас направляют к техподдержке VMware. Однако отметим, что VMware заявляет, что подобных проблем в ее практике еще не было.
Теперь, что касается самой VMware - у них есть отдельная политика технической поддержки "Oracle Support Policy". В ней, в частности, написано, что VMware принимает запросы на техподдержку касательно ВМ Oracle, работающих на vSphere, после чего взаимодействует со службой техподдержки Oracle через TSANet для поиска причины проблемы и решения. Тут важно, что за такие кейсы отвечает сама VMware.
1. Виртуальные машины с СУБД Oracle могут работать на хостах VMware ESX/ESXi, у которых либо все физические процессоры (ядра), либо их часть лицензированы под Oracle. Оптимально, конечно, лицензировать весь хост, однако если это дорого, можно лицензировать и несколько процессоров, после чего привязать конкретные виртуальные машины к физическим процессорам хоста, используя vSphere Client:
Либо используя vSphere Web Client:
Однако, как вы можете прочитать в документе от VMware (см. комментарии к заметке), компания Oracle не признает такого разделения лицензий по процессорам на хосте, хотя сама VMware этим очень недовольна. Поэтому вам придется лицензировать все процессоры хоста, при этом вы там сможете запустить столько экземпляров Oracle, сколько потребуется.
Возможно, эта ситуация в будущем изменится, и можно будет лицензировать отдельные процессоры хоста.
2. Если вы хотите, чтобы виртуальная машина с Oracle перемещалась на другой хост, то все процессоры исходного и целевого хостов должны быть лицензированы Oracle.
3. Что касается кластеров VMware HA/DRS, то тут нужно быть внимательным. Оптимальное решение - это создать отдельный кластер для ВМ с Oracle и лицензировать все процессоры всех хостов в нем, если у вас достаточно виртуальных машин, нагрузки и денег для такой задачи. Если недостаточно - можно лицензировать часть хостов (но, опять-таки, целиком), после чего выставить для них DRS Host Affinity Rules таким образом, чтобы виртуальные машины с Oracle всегда оставались на лицензированных хостах:
Для получения более полной информации о лицензировании Oracle в виртуальной среде VMware vSphere читайте приведенный выше документ.
В данной статье объединены все общедоступные на сегодняшний день расширенные настройки кластера VMware HA (с учетом нововведений механизма) для обеспечения высокой доступности сервисов в виртуальных машинах VMware vSphere 5.0 и более ранних версий. Отказоустойчивость достигается двумя способами: средствами VMware HA на уровне хостов ESXi (на случай отказов оборудования или гипервизора) и средствами VMware VM Monitoring (зависание гостевой операционной системы).
На каждом хосте службой VMware HA устанавливается агент Fault Domain Manager (FDM), который пришел на смену агентам Legato AAM (Automated Availability Manager). В процессе настройки кластера HA один из агентов выбирается как Master, все остальные выполняют роль Slaves (мастер координирует операции по восстановлению, а в случае его отказа выбирается новый мастер). Теперь больше нет primary/secondary узлов. Одно из существенных изменений VMware HA - это Datastore Heartbeating, механизм, позволяющий мастер-серверу определять состояния хост-серверов VMware ESXi, изолированных от сети, но продолжающих работу с хранилищами.
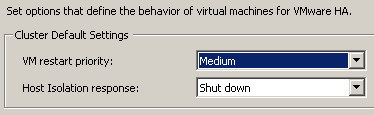
Задать Advanced Options для VMware HA (иногда их называют Advanced Settings) можно, нажав правой кнопкой на кластер в vSphere Client и далее выбрав пункт "Edit Settings", где уже нужно вводить их как указано на картинке:
Список Advanced Options для VMware HA, действующих только в vSphere 5.0:
das.ignoreinsufficienthbdatastore - определяет, будет ли игнорировано сообщение о количестве имеющихся Heartbeat-хранилищ, которое меньше сконфигурированного в настройке das.heartbeatdsperhost (по умолчанию - это 2 хранилища). То есть если Heartbeat-хранилище присутствует только одно - будет выведено следующее сообщение:
Выставление значения этого параметра в true уберет это предупреждение из vSphere Client.
das.heartbeatdsperhost - определяет количество Heartbeat-хранилищ, которое можно регулировать данной настройкой (допустимые значения - от 2 до 5). По умолчанию, данное значение равно 2.
das.config.log.maxFileNum - определяет количество лог-файлов, в пределах которого будет происходить их ротация.
das.config.log.maxFileSize - максимальный размер лог-файла, задаваемый в байтах.
das.config.log.directory - путь для хранения лог-файлов VMware HA. При задании настроек логов следует руководствоваться следующей таблицей (подробнее читайте тут на последних страницах):
das.config.fdm.deadIcmpPingInterval - интервал между пингами по протоколу ICMP для определения доступности Slave-хоста ESXi в сети со стороны Master, в случае, если нет коммуникации с FDM-агентом Slave-хоста (используется, чтобы определить - сломался агент FDM или хост вышел из строя). По умолчанию задано значение 10 (секунд).
das.config.fdm.icmpPingTimeout - таймаут, который хост (мастер) ожидает перед получением ответа на пинг, при неполучении которого он считает один из хостов недоступным из сети (то есть время, которое он дает для ответа на пинг, после чего начинаются операции по восстановлению ВМ). По умолчанию задано значение 5 (секунд).
das.config.fdm.hostTimeout - таймаут, который мастер ожидает после события неполученного хартбита от FDM-агента хоста после чего он определяет является ли хост отказавшим (dead), изолированным (isolated) или в другом сегменте разделенной сети (partitioned). По умолчанию задано значение 10 (секунд). Сами же хартбиты между мастером и slave-хостами посылаются каждую секунду.
das.config.fdm.stateLogInterval - частота записи состояния кластера в лог-файл. По умолчанию выставлено в 600 (секунд).
das.config.fdm.ft.cleanupTimeout - когда сервер vCenter инициирует запуск Secondary-машины, защищенной с помощью Fault Tolerance, он информирует мастера HA о том, что он начал этот процесс. Далее мастер ждет время, выставленное в этой настройке, и определяет запустилась ли эта виртуальная машина. Если не запустилась - то он самостоятельно инициирует ее повторный запуск. Такая ситуация может произойти, когда во время настройки FT вдруг вышел из строя сервер vCenter. По умолчанию задано значение 900 (секунд).
das.config.fdm.storageVmotionCleanupTimeout - когда механизм Storage vMotion перемещает виртуальную машину с/на хосты ESX 4.1 или более ранней версии, может возникнуть конфликт, когда HA считает, что это не хранилище ВМ переместилось, а сама ВМ отказала. Поэтому данная настройка определяет, сколько времени мастеру нужно подождать, чтобы завершилась операция Storage vMotion, перед принятием решения о перезапуске ВМ. См. также нашу заметку тут. По умолчанию задано значение 900 (секунд).
das.config.fdm.policy.unknownStateMonitorPeriod - определяет сколько агент мастера ждет отклика от виртуальной машины, перед тем как посчитать ее отказавшей и инициировать процедуру ее перезапуска.
das.config.fdm.event.maxMasterEvents - определяет количество событий, которые хранит мастер операций HA.
das.config.fdm.event.maxSlaveEvents - определяет количество событий, которые хранят Slave-хосты HA.
Список Advanced Options для VMware HA в vSphere 5.0 и более ранних версиях:
das.defaultfailoverhost- сервер VMware ESXi (задается короткое имя), который будет использоваться в первую очередь для запуска виртуальных машин в случае сбоя других ESXi. Если его емкости недостаточно для запуска всех машин – VMware HA будет использовать другие хосты.
das.isolationaddress[n] - IP-адрес, который используется для определения события изоляции хостов. По умолчанию, это шлюз (Default Gateway) сервисной консоли. Этот хост должен быть постоянно доступен. Если указано значение n, например, das.isolationaddress2, то адрес также используется на проверку события изоляции. Можно указать до десяти таких адресов (диапазон n от 1 до 10).
das.failuredetectioninterval - значение в миллисекундах, которое отражает время, через которое хосты VMware ESX Server обмениваются хартбитами. По умолчанию равно 1000 (1 секунда).
das.usedefaultisolationaddress - значение-флаг (true или false, по умолчанию - true), которое говорит о том, использовать ли Default Gateway как isolation address (хост, по которому определяется событие изоляции). Параметр необходимо выставить в значение false, если вы планируете использовать несколько isolation-адресов от das.isolationaddress1 до das.isolationaddress10, чтобы исключить шлюз из хостов, по которым определяется событие изоляции.
das.powerOffonIsolation - значение флаг (true или false), используемое для перекрытия настройки isolation response. Если установлено как true, то действие «Power Off» - активно, если как false - активно действие «Leave powered On». Неизвестно, работает ли в vSphere 5.0, но в более ранних версиях работало.
das.vmMemoryMinMB - значение в мегабайтах, используемое для механизма admission control для определения размера слота. При увеличении данного значения VMware HA резервирует больше памяти на хостах ESX на случай сбоя. По умолчанию, значение равно 256 МБ.
das.vmCpuMinMHz - значение в мегагерцах, используемое для механизма admission control для определения размера слота. При увеличении данного значения VMware HA резервирует больше ресурсов процессора на хостах ESX на случай сбоя. По умолчанию, значение равно 256 МГц (vSphere 4.1) и 32 МГц (vSphere 5).
das.conservativeCpuSlot - значение-флаг (true или false), определяющее как VMware HA будет рассчитывать размер слота, влияющего на admission control. По умолчанию установлен параметр false, позволяющий менее жестко подходить к расчетам. Если установлено в значение true – механизм будет работать как в VirtualCenter 2.5.0 и VirtualCenter 2.5.0 Update 1. Неизвестно, осталась ли эта настройка актуальной для vSphere 5.0.
das.allowVmotionNetworks - значение-флаг, позволяющее или не позволяющее использовать физический адаптер, по которому идет трафик VMotion (VMkernel + VMotion Enabled), для прохождения хартбитов.Используется только для VMware ESXi. По умолчанию этот параметр равен false, и сети VMotion для хартбитов не используются. Если установлен в значение true – VMware HA использует группу портов VMkernel с включенной опцией VMotion.
das.allowNetwork[n] – имя интерфейса сервисной консоли (например, ServiceConsole2), который будет использоваться для обмена хартбитами. n – номер, который отражает в каком порядке это будет происходить. Важно! - не ошибитесь, НЕ пишите das.allowNetworkS.
das.isolationShutdownTimeout - значение в секундах, которое используется как таймаут перед срабатыванием насильственного выключения виртуальной машины (power off), если не сработало мягкое выключение из гостевой ОС (shutdown). В случае выставления isolation response как shutdown, VMware HA пытается выключить ее таким образом в течение 300 секунд (значение по умолчанию). Обратите внимание, что значение в секундах, а не в миллисекундах.
das.ignoreRedundantNetWarning - значение-флаг (true или false, по умолчанию false), который при установке в значение false отключает нотификацию об отсутствии избыточности в сети управления («Host xxx currently has no management network redundancy»). По умолчанию установлено в значение false.
Настройки VM Monitoring для VMware HA платформы vSphere 5.0 и более ранних версий:
das.vmFailoverEnabled - значение-флаг (true или false). Если установлен в значение true – механизм VMFM включен, если false – выключен. По умолчанию установлено значение false.
das.FailureInterval - значение в секундах, после которого виртуальная машина считается зависшей и перезагружается, если в течение этого времени не получено хартбитов. По умолчанию установлено значение 30.
das.minUptime - значение в секундах, отражающее время, которое дается на загрузку виртуальной машины и инициализацию VMware Tools для обмена хартбитами. По умолчанию установлено значение 120.
das.maxFailures - максимальное число автоматических перезагрузок из-за неполучения хартбитов, допустимое за время, указанное в параметре das.maxFailureWindow. Если значение das.maxFailureWindow равно «-1», то das.maxFailures означает абсолютное число отказов или зависаний ОС, после которого автоматические перезагрузки виртуальной машины прекращаются, и отключается VMFM. По умолчанию равно 3.
das.maxFailureWindow - значение, отражающее время в секундах, в течение которого рассматривается значение параметра das.maxFailures. По умолчанию равно «-1». Например, установив значение 86400, мы получим, что за сутки (86400 секунд) может произойти 3 перезапуска виртуальной машины по инициативе VMFM. Если перезагрузок будет больше, VMFM отключится. Значение параметра das.maxFailureWindow может быть также равно «-1». В этом случае время рассмотрения числа отказов для отключения VMFM – не ограничено.
Настройки, которые больше не действуют в vSphere 5.0:
das.failuredetectiontime
Работает только в vSphere 4.1 и более ранних версиях (см. ниже).
Раньше была настройка das.failuredetectiontime - это значение в миллисекундах, которое отражает время, через которое VMware HA признает хост изолированным, если он не получает хартбитов (heartbeats) от других хостов и isolation address недоступен. После этого срабатывает действие isolation response, которое выставляется в параметрах кластера в целом, либо для конкретной виртуальной машины. По умолчанию, значение равно 15000 (15 секунд). Рекомендуется увеличить это время до 60000 (60 секунд), если с настройками по умолчанию возникают проблемы в работе VMware HA. Если у вас 2 интерфейса обмена хартбитами - можно оставить 15 секунд.
В VMware vSphere 5, в связи с тем, что алгоритм HA был полностью переписан, настройка das.failuredetectiontime для кластера больше не акутальна.
Теперь все работает следующим образом (см. также новые das-параметры, которые были описаны выше).
Наступление изоляции хост-сервера ESXi, не являющегося Master (т.е. Slave):
Время T0 – обнаружение изоляции хоста (slave).
T0+10 сек – Slave переходит в состояние "election state" (выбирает "сам себя").
T0+25 сек – Slave сам себя назначает мастером.
T0+25 сек – Slave пингует адрес, указанный в "isolation addresses" (по умолчанию, это Default Gateway).
T0+30 сек – Slave объявляет себя изолированным и вызывает действие isolation response, указанное в настройках кластера.
Наступление изоляции хост-сервера ESXi, являющегося Master:
T0 – обнаружение изоляции хоста (master).
T0 – Master пингует адрес, указанный в "isolation addresses" (по умолчанию, это Default Gateway).
T0+5 сек – Master объявляет себя изолированным и вызывает действие isolation response, указанное в настройках кластера.
Как мы видим, алгоритм для мастера несколько другой, чтобы при его изоляции остальные хосты ESXi смогли быстрее начать выборы и выбрать нового мастера. После падения мастера, новый выбранный мастер управляет операциями по восстановлению ВМ изолированного хоста. Если упал Slave - то, понятное дело, восстановлением его ВМ управляет старый мастер. И да, помним, что машины будут восстанавливаться, только если в Isolation Responce стоит Shutdown или Power Off, чтобы хост мог их погасить.
das.bypassNetCompatCheck
Работает только в vSphere 4.1 и более ранних версиях (см. ниже).
Это значение-флаг (true или false, по умолчанию false), который будучи установлен в значение true позволяет обойти дополнительную проверку на совместимость с HA. В VirtualCenter Update 2 была введена проверка на совместимость подсетей, по которым ходят хартбиты. Возникала ошибка: «HA agent on in cluster in has an error Incompatible HA Network: Consider using the Advanced Cluster Settings das.allowNetwork to control network usage». Теперь, если сети считаются несовместимыми с точки зрения HA, однако маршрутизируемыми – новая опция поможет осуществить корректную настройку кластера.
Таги: VMware, HA, FDM, VMachines, ESXi, Обучение, vSphere
Вот тут те же IDC пишут, что к Virtualization 3.0 развитый мир придет не раньше 2013 года, а главными ее признаками будут полностью виртуализованный ЦОД, объединяющий сервисы собственного внутреннего облака и внешних облаков сервис-провайдеров, адаптивная инфраструктура (если проще - то самооптимизирующаяся) и сервисно-ориентированная бизнес-модель.
Вообще, это интересная штука - классификация зрелости виртуализации по верисям - Virtualization 1.0, 2.0 и 3.0. Если кратко, то эти этапы, с точки зрения признаков, преимуществ и используемых технологий, на примере VMware я бы охарактеризовал так:
Virtualization 1.0 - консолидация
Аудит собственной инфраструктуры физических серверов
Выбор платформы - базовая консолидация серверов (низкая и средняя критичность)
Экономия капитальных и операционных затрат (серверы, электричество), но больший фокус на капитальных
Быстрый экспансивный рост виртуальной инфраструктуры (зачастую, бесконтрольный)
Применение разнородных скриптов и стороннего ПО для решения специфических задач
Virtualization 2.0 - управление
Унификация развертывания новых серверов в виртуальных машинах (то есть, запрос на создание сервера формируется в виде вычислительных ресурсов и хранилища - без привязки к оборудованию). Автоматизация процессов выделения ВМ пользователям
Фокус на операционных затратах (сокращение издержек на управление, обслуживание, мониторинг, резервное копирование и т.п.) и отдаче от возможностей ПО виртуализации (интенсификация, увеличение коэффициента консолидации)
Внедрение новых средств управления виртуальной средой (мониторинг, отчетность, интеграция с существующим ПО для управления датацентром)
Унификация процедур управления: обновлений, настройки конфигурации хостов и ВМ, шаблоны рабочих процессов (например, VMware Orchestrator, Host Profiles, запланированные задачи и т.п.)
Управляемое планирование мощностей виртуальной среды (Capacity Planning)
Построение модели TCO/ROI дл виртуальной инфраструктуры (сколько обходится ее содержание и как окупаются инвестиции)
Внедрение специализированных средств обеспечения безопасности
Первые производственные внедрения VDI-инфраструктуры (для наименее критичных пользователей)
Расширенные сервисы по отказо- и катастрофоустойчивости инфраструктуры (например, VM Monitoring и VMware SRM + план восстановления после сбоев, репликация ВМ)
Расширенные сервисы управления ресурсами (например, VMware Net I/O Control, Storage I/O Control, DPM и т.п.)
Расширенные сервисы мобильности (Storage vMotion+vMotion между ЦОД, распространение виртуализованных приложений в виде пакетов, Offline Desktops для VDI)
Расширенные сервсиы хранилищ (VMware Storage DRS, профили хранилищ, ярусное хранение данных серверов и виртуальных ПК, VAAI)
Унификация средств решения рутинных задач (например, VMware PowerShell/PowerCLI, Orchestrator)
Первые опыты по формализации внутреннего облака (постоянный учет затрат, соглашения SLA внутри компании, выдача ресурсов по требованию, обслуживание жизненного цикла ВМ)
Первые опыты по использованию сервисов публичных облаков
Virtualization 3.0 - самооптимизация и услуги для бизнеса
Виртуализация Tier 1 систем (самая высокая критичность)
Полная автоматизация операций по управлению виртуальной средой, внедрение средств самооптимизации вычислительных ресурсов, сетей и хранилищ
Унификация использования адаптивных сервисов (например, Storage DRS, SIOC и т.п.)
План для всех видов отказов и простоев в виртуальной инфраструктуре - оформление SLA для пользователей (доступность, производительность и т.п.)
Делегирование части полномочий "повзрослевшим" пользователям (выдача ресурсов по требованию самому себе, порталы самообслуживание, средства управления и контроля)
Непрерывный учет затрат (например, VMware Chargeback), четкое представление о том, сколько стоит 1 МБ и 1 ГГц для соответствующего SLA или Tier, т.е. любая создаваемая ВМ.
Интеграция и федерация (сведение в одну точку управления) средств управления и мониторинга физической и виртуальной среды (от уровня приложений до уровня ЦОД)
Гетерогенные среды виртуализации (например, где-то Hyper-V будет использовать выгоднее, чем VMware с точки зрения TCO) + единые средства управления такими средами
Виртуализация хранилищ SAN (например, EMC VPLEX + интеграция с виртуальной средой)
VDI как стандарт настольных ПК в организации (доставка ПК, клиентский гипервизор + доставка в них виртуализованных приложений) - этот момент, кстати, спорный, т.к. может быть заменен альтернативной облачной концепцией
Оформление внутреннего облака предприятия (учет мощностей и денег, SLA, ITaaS, уровни доступности, классы обслуживания и т.п.) + возможности предоставления услуг внешним организациям, а также аффилированным или дочерним компаниям (зависит от специфики организации)
Расширение использования внешних облаков (SaaS+PaaS+IaaS), механизмы использования ресурсов внешнего облака по требованию
Часто бывает, что от хоста ESX/ESXi нужно отвязать Datastore и LUN, на котором это виртуальное хранилище находится. При этом важно избежать ситуации All Paths Down (APD) - когда на хосте все еще остались пути к устройству, а самого устройства ему больше не презентовано. В этом случае хост ESX/ESXi будет периодически пытаться обратиться к устройству (команды чтения параметров диска) через демон hostd и восстановить пути.
В этом случае из-за APD хоста начнут возникать задержки других задач (поскольку таймауты большие), что может привести к различным негативным эффектам вплоть до отключения хоста от vCenter.
ESX/ESXi 4.1
В версии ESX/ESXi 4.1 демон hostd проверяет том VMFS на доступность прежде чем слать туда команды ввода-вывода (I/Os) Но это не помогает для тех I/O, которые находятся в процессе в то время, когда случилась ситуация APD.
Как описано в KB 1015084, правильно отвязывать LUN с хоста ESX/ESXi 4.1 так (все делается на каждом из хостов):
Разрегистрировать все объекты с этого Datastore (если они там есть), включая шаблоны - правой кнопкой по объекту, Remove from Inventory.
Убедиться, что этот datastore не используют сторонние программы.
Убедиться, что никакие из фичей vSphere для хранилищ (например, Storage I/O Control) больше не используются для этого устройства.
Замаскировать LUN на хосте ESX/ESXi, следуя инструкциям KB 1009449 через модуль PSA (Pluggable Storage Architecture).
Со стороны дискового массива распрезентовать LUN от хоста.
Сделать "Rescan for Datastores" на хосте ESX/ESXi.
Удалить правила маскирования LUN, которые вы сделали на шаге 4 по инструкции в KB1015084.
Убедиться, что не осталось путей к устройству, после того, как вы проделали все эти операции.
Для ESX/ESXi 4.1 процесс достаточно сложный, теперь давайте посмотрим, как это выглядит в ESXi 5.
ESXi 5.0
В ESXi 5.0 появился новый статус Permanent Device Loss (PDL), то есть когда хост считает, что дисковое устройство уже никогда не будет снова подключено, а ситуация APD рассматривается как временный сбой, после которого хост снова увидит пути и устройство.
Чтобы избавиться от сложной процедуры отключения LUN от хостов ESXi, VMware сделала операции detach и unmount в интерфейсе vSphere Client и в командном интерфейсе CLI.
Вот тут можно найти unmount Datastore (но устройство продолжит быть доступным):
А вот тут находится detach для самого устройства:
Как описано в KB 2004605, чтобы у вас не возникло ситуации APD, нужно всего-лишь сделать detach устройства от хоста. Это размонтирует VMFS-том (если там есть какие-нибудь объекты - vSphere Client вам сообщит об этом).
Таким образом правильная последовательность отключения LUN в ESXi 5.0 теперь такова:
Разрегистрировать все объекты с этого Datastore (если они там есть), включая шаблоны - правой кнопкой по объекту, Remove from Inventory.
Убедиться, что этот datastore не используют сторонние программы.
Убедиться, что никакие из фичей vSphere для хранилищ (например, Storage I/O Control или Storage DRS) больше не используются для этого устройства.
Сделать detach устройства на хосте ESXi, что также автоматически повлечет за собой операцию unmount.
Со стороны дискового массива распрезентовать LUN от хоста.
Сделать "Rescan for Datastores" на хосте ESXi.
Ну и в качестве дополнительного материала можно почитать вот эти статьи:
Интересный момент обнаружился на блогах компании VMware. Оказывается, если вы используете в кластере VMware HA разные версии платформы VMware ESXi (например, 4.1 и 5.0), то при включенной технологии Storage DRS (выравнивание нагрузки на хранилища), вы можете повредить виртуальный диск вашей ВМ, что приведет к его полной утере.
In clusters where Storage vMotion is used extensively or where Storage DRS is enabled, VMware recommends that you do not deploy vSphere HA. vSphere HA might respond to a host failure by restarting a virtual machine on a host with an ESXi version different from the one on which the virtual machine was running before the failure. A problem can occur if, at the time of failure, the virtual machine was involved in a Storage vMotion action on an ESXi 5.0 host, and vSphere HA restarts the virtual machine on a host with a version prior to ESXi 5.0. While the virtual machine might power on, any subsequent attempts at snapshot operations could corrupt the vdisk state and leave the virtual machine unusable.
По русски это выглядит так:
Если вы широко используете Storage vMotion или у вас включен Storage DRS, то лучше не использовать кластер VMware HA. Так как при падении хост-сервера ESXi, HA может перезапустить его виртуальные машины на хостах ESXi с другой версией (а точнее, с версией ниже 5.0, например, 4.1). А в это время хост ESXi 5.0 начнет Storage vMotion, соответственно, во время накатывания последовательности различий vmdk (см. как работает Storage vMotion) машина возьмет и запустится - и это приведет к порче диска vmdk.
Надо отметить, что такая ситуация, когда у вас в кластере используется только ESXi 5.0 и выше - произойти не может. Для таких ситуаций HA и Storage vMotion полностью совместимы.
Скоро нам придется участвовать в интереснейшем проекте - построение "растянутого" кластера VMware vSphere 5 на базе технологии и оборудования EMC VPLEX Metro с поддержкой возможностей VMware HA и vMotion для отказоустойчивости и распределения нагрузки между географически распределенными ЦОД.
Вообще говоря, решение EMC VPLEX весьма новое и анонсировано было только в прошлом году, но сейчас для нашего заказчика уже едут модули VPLEX Metro и мы будем строить active-active конфигурацию ЦОД (расстояние небольшое - где-то 3-5 км) для виртуальных машин.
Для начала EMC VPLEX - это решение для виртуализации сети хранения данных SAN, которое позволяет объединить ресурсы различных дисковых массивов различных производителей в единый логический пул на уровне датацентра. Это позволяет гибко подходить к распределению дискового пространства и осуществлять централизованный мониторинг и контроль дисковых ресурсов. Эта технология называется EMC VPLEX Local:
С физической точки зрения EMC VPLEX Local представляет собой набор VPLEX-директоров (кластер), работающих в режиме отказоустойчивости и балансировки нагрузки, которые представляют собой промежуточный слой между SAN предприятия и дисковыми массивами в рамках одного ЦОД:
В этом подходе есть очень много преимуществ (например, mirroring томов двух массивов на случай отказа одного из них), но мы на них останавливаться не будем, поскольку нам гораздо более интересна технология EMC VPLEX Metro, которая позволяет объединить дисковые ресурсы двух географически разделенных площадок в единый пул хранения (обоим площадкам виден один логический том), который обладает свойством катастрофоустойчивости (и внутри него на уровне HA - отказоустойчивости), поскольку данные физически хранятся и синхронизируются на обоих площадках. В плане VMware vSphere это выглядит так:
То есть для хост-серверов VMware ESXi, расположенных на двух площадках есть одно виртуальное хранилище (Datastore), т.е. тот самый Virtualized LUN, на котором они видят виртуальные машины, исполняющиеся на разных площадках (т.е. режим active-active - разные сервисы на разных площадках но на одном хранилище). Хосты ESXi видят VPLEX-директоры как таргеты, а сами VPLEX-директоры являются инициаторами по отношению к дисковым массивам.
Все это обеспечивается технологией EMC AccessAnywhere, которая позволяет работать хостам в режиме read/write на массивы обоих узлов, тома которых входят в общий пул виртуальных LUN.
Надо сказать, что технология EMC VPLEX Metro поддерживается на расстояниях между ЦОД в диапазоне до 100-150 км (и несколько более), где возникают задержки (latency) до 5 мс (это связано с тем, что RTT-время пакета в канале нужно умножить на два для FC-кадра, именно два пакета необходимо, чтобы донести операцию записи). Но и 150 км - это вовсе немало.
До появления VMware vSphere 5 существовали некоторые варианты конфигураций для инфраструктуры виртуализации с использованием общих томов обоих площадок (с поддержкой vMotion), но растянутые HA-кластеры не поддерживались.
С выходом vSphere 5 появилась технология vSphere Metro Storage Cluster (vMSC), поддерживаемая на сегодняшний день только для решения EMC VPLEX, но поддерживаемая полностью согласно HCL в плане технологий HA и vMotion:
Обратите внимание на компонент посередине - это виртуальная машина VPLEX Witness, которая представляет собой "свидетеля", наблюдающего за обоими площадками (сам он расположен на третьей площадке - то есть ни на одном из двух ЦОД, чтобы его не затронула авария ни на одном из ЦОД), который может отличить падения линка по сети SAN и LAN между ЦОД (экскаватор разрезал провода) от падения одного из ЦОД (например, попадание ракеты) за счет мониторинга площадок по IP-соединению. В зависимости от этих обстоятельств персонал организации может предпринять те или иные действия, либо они могут быть выполнены автоматически по определенным правилам.
Теперь если у нас выходит из строя основной сайт A, то механизм VMware HA перезагружает его ВМ на сайте B, обслуживая их ввод-вывод уже с этой площадки, где находится выжившая копия виртуального хранилища. То же самое у нас происходит и при массовом отказе хост-серверов ESXi на основной площадке (например, дематериализация блейд-корзины) - виртуальные машины перезапускаются на хостах растянутого кластера сайта B.
Абсолютно аналогична и ситуация с отказами на стороне сайта B, где тоже есть активные нагрузки - его машины передут на сайт A. Когда сайт восстановится (в обоих случаях с отказом и для A, и для B) - виртуальный том будет синхронизирован на обоих площадках (т.е. Failback полностью поддерживается). Все остальные возможные ситуации отказов рассмотрены тут.
Если откажет только сеть управления для хостов ESXi на одной площадке - то умный VMware HA оставит её виртуальные машины запущенными, поскольку есть механизм для обмена хартбитами через Datastore (см. тут).
Что касается VMware vMotion, DRS и Storage vMotion - они также поддерживаются при использовании решения EMC VPLEX Metro. Это позволяет переносить нагрузки виртуальных машин (как вычислительную, так и хранилище - vmdk-диски) между ЦОД без простоя сервисов. Это открывает возможности не только для катастрофоустойчивости, но и для таких стратегий, как follow the sun и follow the moon (но 100 км для них мало, специально для них сделана технология EMC VPLEX Geo - там уже 2000 км и 50 мс latency).
Самое интересное, что скоро приедет этот самый VPLEX на обе площадки (где уже есть DWDM-канал и единый SAN) - поэтому мы все будем реально настраивать, что, безусловно, круто. Так что ждите чего-нибудь про это дело интересного.
Таги: VMware, HA, Metro, EMC, Storage, vMotion, DRS, VPLEX
Одно из существенных изменений, Datastore Heartbeating - механизм, позволяющий мастер-серверу определять состояния хост-серверов VMware ESXi, изолированных от сети, но продолжающих работу с хранилищами. Напомним, что в качестве heartbeat-хранилищ выбираются два, и они могут быть определены пользователем. Выбираются они так: во-первых, они должны быть на разных массивах, а, во-вторых, они должны быть подключены ко всем хостам.
Если у вас доступно общее хранилище только одно, вы получите такое предупреждение в vSphere Client:
Теперь еще один момент, на который хочется обратить внимание. Помните, что в настройках VMware HA есть варианты выбора действия для хост-сервера по отношении к своим виртуальным машинам в том случае, когда он обнаруживает, что изолирован от сети (параметр Isolation Responce):
Напомним, что Isolation Responce может принимать следующие значения:
Leave powered on (по умолчанию в vSphere 5 - оптимально для большинства сценариев)
Power off
Shutdown
Выбирать правильную настройку нужно следующим образом:
Если наиболее вероятно что хост ESXi отвалится от общей сети, но сохранит коммуникацию с системой хранения, то лучше выставить Power off или Shutdown, чтобы он мог погасить виртуальную машину, а остальные хосты перезапустили бы его машину с общего хранилища после очистки локов на томе VMFS или NFS (вот кстати, что происходит при отваливании хранища).
Если вы думаете, что наиболее вероятно, что выйдет из строя сеть сигналов доступности (например, в ней нет избыточности), а сеть виртуальных машин будет функционировать правильно (там несколько адаптеров) - ставьте Leave powered on.
Разницу между Power off и Shutdown многие из вас знают - во втором случае машина выключается средствами гостевой системы, а в первом случае - это жесткое выключение средствами хост-сервера. Казалось бы, лучше всего ставить второй вариант (Shutdown). Но это не всегда так. Дело в том, что при действии shutdown у гостевой ОС может не получиться погасить систему (например, вылетит exception или еще что). В этом случае хост ESXi будет пытаться сделать shutdown в течение 5 минут до того, как он уже сделает действие power off.
Это приведет к тому, что время восстановления работоспособности сервиса вполне может увеличиться на 5 минут, что может быть критично для некоторых задач (с высокими требованиями к RTO). Зато в случае shutdown у вас произойдет корректное завершение работы сервера, а при power off могут не сохраниться данные, нарушиться консистентность и т.п. Выбирайте.
Пало-Альто, Калифорния, 7 сентября 2011 - Компания VMware, мировой лидер в области виртуализации и облачных вычислений, объявила о поступлении в продажу VMware vSphere 5. Новая версия продукта включает в себя около 200 нововведений и усовершенствований, которые позволят пользователям преобразовать существующие ИТ-системы, повысив эффективность капиталовложений и операционное быстродействие. Таги:
Режим SplitRx mode, который позволяет увеличить производительность сетевого взаимодействия для некоторых нагрузок
Функция VMX swap, которая уменьшает резервирование памяти для ВМ
Миграция vMotion по нескольким сетевым адаптерам (vmknics)
В документы присутствуют следующие темы:
Выбор оборудования для развертывания vSphere
Управление электропитанием
Настройка ESXi 5 для улучшения производительности
Настройка гостевой ОС для улучшения производительности
Настройка vCenter 5 и его базы данных для улучшения производительности
Производительность vMotion и Storage vMotion
Производительность Distributed Resource Scheduler (DRS) и Distributed Power Management (DPM)
Компоненты High Availability (HA), Fault Tolerance (FT) и VMware vCenter Update Manager
Документ обязателен к прочтению администраторам средних и крупных инфраструктур VMware vSphere 5. Кроме того, напомним о следующих новых документах о производительности платформы:
Мы уже много писали о различных технических аспектах новой версии серверной платформы виртуализации VMware vSphere 5 и особенностях лицензирования, но в этой статье постараемся сделать суммарный обзор функциональности различных изданий продукта, краткое описание состава пакетов ПО (Acceleration Kits и Essentials), а также детально рассмотреть особенности лицензирования.
Компания Oracle анонсировала доступность новой версии своей серверной платформы виртуализации Oracle VM 3.0.
В новой версии платформы появилось множество улучшений и нововведений с точки зрения хранилищ и сетевого взаимодействия, управление ресурсами на базе политик (DRS/DPM) и полностью новый пользовательский интерфейс. Надо отметить, что Oracle VM 3.0 остается единственным сертифицированным решением по виртуализации для запуска продуктов Oracle в виртуальных машинах. Кроме того, Oracle VM 3.0 является бесплатной платформой виртуализации с платной поддержкой.
Итак, новые возможности Oracle VM 3.0:
Функции балансировки нагрузки виртуальных машин на серверы пула (Distributed Resource Scheduling) за счет перемещения средствами "горячей" миграции виртуальных машин с более загруженных серверов на менее загруженные.
Возможности управления питанием (Distributed Power Management) - для экономии энергии серверов виртуализации. При спаде нагрузки - серверы отключаются, при росте - включаются.
Централизованное управление конфигурацией виртуальных сетей средствами Oracle VM Manager
Фреймворк Storage connect, позволяющий использовать возможности систем хранения напрямую из Oracle VM Manager. Соответствующие плагины доступны для хранилищ Fujitsu, Hitachi Data Systems и NetApp. Для модулей SUN ZFS Storage Appliances и Pillar Axiom 600 SAN плагины находятся в разработке.
Автообнаружение серверов и хранилищ.
Гипервизор Xen 4.0.
Обновленные компоненты ядра Dom0 command и control kernel.
Поддержка до 160 CPU и 2 TB памяти для хост-серверов Oracle VM.
Поддержка до 128 vCPU в виртуальной машине.
Кластерная файловая система OCFS2 1.8.
Поддержка формата Open Virtualization Format (OVF) для развертывания виртуальных машин.
Новый веб-интерфейс Oracle VM Manager с новым GUI (на базе Oracle Application Development Framework (ADF) и Oracle WebLogic Server 11g).
Фреймворк для работы с запланированными задачами.
Расширенное протоколирование событий.
Статистики производительности для CPU,memory, disk и network - для хост-сервров и виртуальных машин.
Кроме того, значительно расширился список шаблонов для Oracle VM - готовых виртуальных машин с приложениями Oracle, которые можно развернуть на данной платформе.
Вы уже читали, что в VMware vSphere 5 механизм отказоустойчивости виртуальных машин VMware High Availability претерпел значительные изменения. Точнее, он не просто изменился - его полностью переписали с нуля. То есть переделали совсем, изменив логику работы, принцип действия и убрав многие из существующих ограничений. Давайте взглянем поподробнее, как теперь работает новый VMware HA с агентами Fault Domain Manager...
Таги: VMware, vSphere, HA, Update, ESXi, Storage, vCenter, FDM

 RSS
RSS